GINI coeficient#
Metric used to evaluate the quality of classification algorithms.
import pandas as pd
import numpy as np
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
from statsmodels.distributions.empirical_distribution import ECDF
np.random.seed(10)
Content#
Basic GINI definition#
Today, GINI is usually expressed through the ROC AUC, but in fact GINI originally had a separate definition through CAP curve.
GINI for some model, is the ratio of the areas between the CAP curve of the model and the random CAP curve to the area between the ideal CAP and the random CAP.
Graphical representation of GINI#
plot_ss = 10000
np.random.seed(3)
random_range = np.random.rand(plot_ss)
plot_data = pd.DataFrame({
"p_hat" : random_range,
"y" : map(
lambda r_val: np.random.choice(
[0, 1], p = [1 - r_val, r_val]
),
random_range
)
})
plot_data.sort_values("y",inplace = True, ascending = False)
plot_data["p_hat_ideal"] = np.linspace(1,0, plot_data.shape[0])
fpr, or_tpr, t = roc_curve(
plot_data["y"], plot_data["p_hat"],
drop_intermediate = False
)
fpr, id_tpr, t = roc_curve(
plot_data["y"], plot_data["p_hat_ideal"],
drop_intermediate = False
)
CAP_x = np.arange(len(or_tpr))/len(or_tpr)
plt.figure(figsize = [10,7])
plt.plot(CAP_x, or_tpr, linewidth = 5)
plt.plot(CAP_x, id_tpr, linewidth = 5)
plt.plot(
[0,1], [0,1], color = "red",
linestyle = "dashed",
linewidth = 5
)
plt.fill_between(
np.arange(len(or_tpr))/len(or_tpr),
or_tpr,
np.arange(len(or_tpr))/len(or_tpr),
hatch = "//",
alpha = 0
)
plt.fill_between(
np.arange(len(or_tpr))/len(or_tpr),
id_tpr,
np.arange(len(or_tpr))/len(or_tpr),
hatch = "\\\\",
alpha = 0
)
plt.xlabel("Percentage of observations", fontsize = 15)
plt.ylabel("$TPR$", fontsize = 15)
plt.xlim([0,1])
plt.ylim([-0.005,1.005])
plt.legend(
[
"Model's CAP", "Ideal CAP",
"Random CAP", "A", "B"
],
fontsize = 14
)
plt.show()
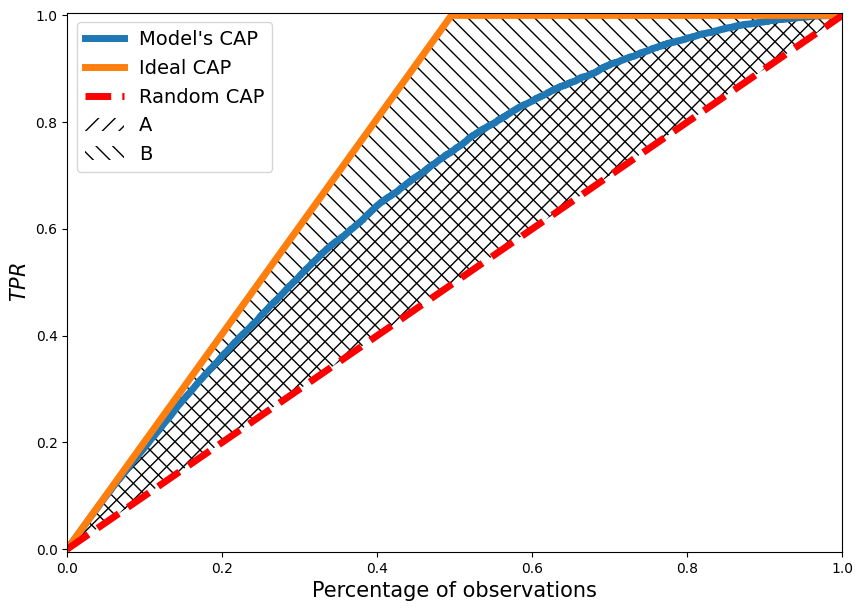
Following the notations of the areas in the figure, we obtain:
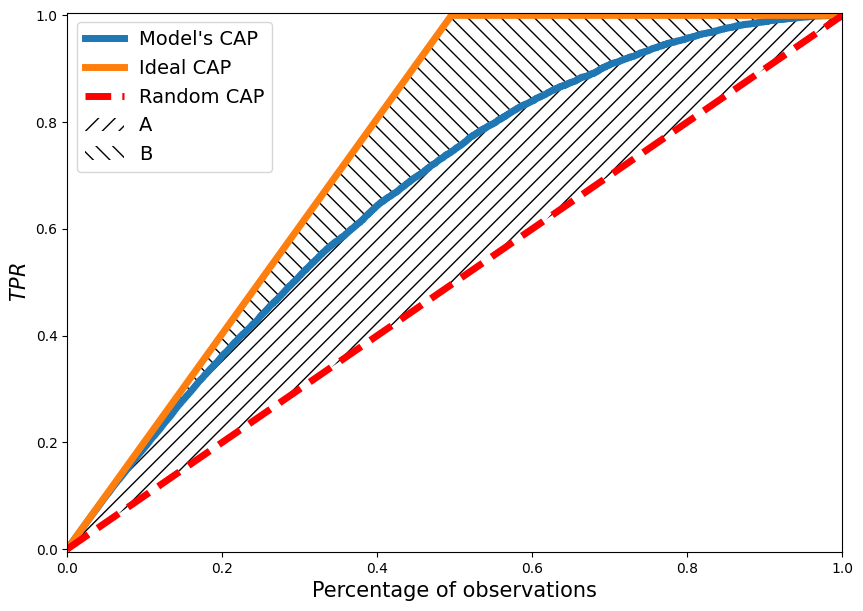
Or by using the alternative designation of areas (for reasons not yet known, especially popular)
plt.figure(figsize = [10,7])
plt.plot(CAP_x, or_tpr, linewidth = 5)
plt.plot(CAP_x, id_tpr, linewidth = 5)
plt.plot(
[0,1], [0,1], color = "red",
linestyle = "dashed",
linewidth = 5
)
plt.fill_between(
np.arange(len(or_tpr))/len(or_tpr),
or_tpr,
np.arange(len(or_tpr))/len(or_tpr),
hatch = "//",
alpha = 0
)
plt.fill_between(
np.arange(len(or_tpr))/len(or_tpr),
id_tpr,
or_tpr,
hatch = "\\\\",
alpha = 0
)
plt.xlabel("Percentage of observations", fontsize = 15)
plt.ylabel("$TPR$", fontsize = 15)
plt.xlim([0,1])
plt.ylim([-0.005,1.005])
plt.legend(
[
"Model's CAP", "Ideal CAP",
"Random CAP", "A", "B"
],
fontsize = 14
)
plt.show()
\(GINI\) as formula#
We have already given a geometric definition of \(GINI\), but for software implementation of computations or for rigorous proofs we would rather use the analytical notation of this quantity.
Area under model \(CUP\)#
First, let’s deal with the numerator of the GINI. We need to express the area under the CUP curve, which we denote by \(AUC_{cap}\).
Let for some set of objects numbered \(i \in \overline{1,n}\) we have obtained some variable \(p_i\) which is the greater the higher the probability of occurrence of the predicted feature \(y_i\). Let objects have been sorted in descending order, so \(p_i \geq p_{i+1}, i \in \overline{1,n-1}\). For example, it might look like the table below.
\(i\) |
\(p_i\) |
\(y_i\) |
\(i/n\) |
\(TPR_i\) |
\(FPR_i\) |
|---|---|---|---|---|---|
1 |
0.8 |
1 |
0.2 |
1/3 |
0 |
2 |
0.7 |
1 |
0.4 |
2/3 |
0 |
3 |
0.6 |
0 |
0.6 |
2/3 |
1/2 |
4 |
0.4 |
0 |
0.8 |
2/3 |
1 |
5 |
0.2 |
1 |
1 |
1 |
1 |
The area under an arbitrary curve \(AUC\) which is the set of points \((x_i,y_i)\) connected by lines can be written as:
In \(CAP\) curve case on the abscissa is the fraction of observations for which \(p_i\) is greater than some threshold or \(i/n\), on the ordinate \(TPR_i\). So assuming that \(TPR_0 = 0\) we obtain the analytical notation \(AUC_{cap}\):
Obviously, the area between the \(CUP\) curve of the estimated model and the \(CUP\) curve of the random classifier is then expressed:
Area under ideal \(CUP\)#
Now let’s deal with the denominator of the \(CAP\) curve.
In the general case, the ideal \(CAP\) curve takes the form displayed by the following cell:
y_rel_ideal = [0, 1/3, 2/3, 1, 1, 1]
x_rel = [i/5 for i in range(6)]
plt.figure(figsize = [10, 7])
plt.plot(x_rel, y_rel_ideal)
plt.fill_between(
[0, 0.6], [0, 1], [0,0],
alpha = 0, hatch = "//"
)
plt.fill_between(
[0.6, 1], [0, 0], [1,1],
alpha = 0, hatch = "\\\\"
)
plt.yticks([0, 1])
plt.xticks(
[0, 0.6, 1],
["0", "$\gamma$", "1"],
fontsize = 14
)
plt.title(
"Ideal CAP curve",
fontsize = 15
)
plt.grid()
plt.xlabel("Percentage of observations", fontsize = 15)
plt.show()
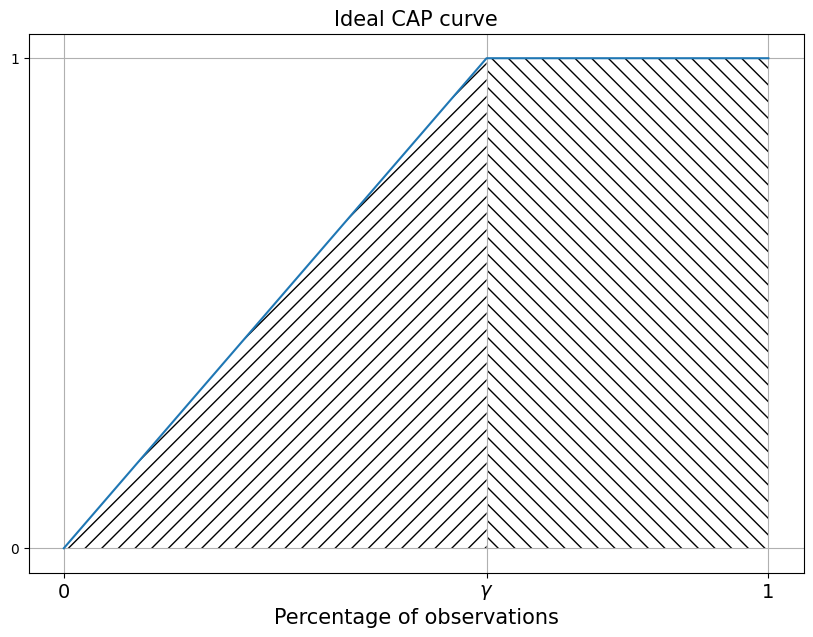
All observations with feature manifestation have greater \(p_i\) than without feature manifestation. Therefore, the \(CAP\) curve grows until all objects in which the manifestation of the investigated trait is observed are finished. So in finishes it growth in point:
It turns out that this area decomposes into 2 figures:
A triangle, highlighted by a hatching slanted to the left;
A rectangle marked by a hatching slanted to the right.
And can be written:
Then the area between the ideal CAP curve and the random CAP curve is:
Or by substituting \(\gamma\):
\(GINI\)#
Finally, combine the previous two steps to write \(GINI\):
Or by omitting conversions:
\(GINI\) & \(AUC_{roc}\) relation#
All of the above refers to the basic definition of the \(GINI\) coefficient. But today in kaggle and in the industry, \(GINI\) is more often expressed through \(AUC_{roc}\):
In my practice I encountered a situation when I was counting GINI using the formula familiar today, and my colleagues used a more classical formula, as a result of which there were conflicts in which I was accused of using the wrong formula. Therefore, I will further prove that both approaches to calculating GINI always lead to the same result.
So we need to prove the statement \((3.1)\).
Let us denote at once that \(FPR_0=TPR_0=0\) - values that meet the maximum threshold where none of the values can be assigned to a positive class.
Let’s write the area under the ROC of the curve, which will be the exponent \(AUC_{roc}\):
We will work with the left part of the identity:
Let’s discuss the properties of expression:
\(FPR\) (the fraction of false positive predictions) increases only for predictions without the manifestation of the trait. And, for an observation without the manifestation of the trait, it increases by the fraction that is occupied by one observation without manifestation of the trait:
Where \((n-\sum_j^n y_j)\) - number of observations without the trait, тогда \((\frac{1}{n-\sum_j^n y_j})\) - the proportion of one observation in observations with a manifestation of the trait.
Then the expression \((3.3)\) can be rewritten as follows:
That is, summation can be performed only for terms for which \(y_{i+1}=0\), all other terms will be zero. Moreover, in non-zero terms one of the multipliers is a constant with respect to the summation operator.
Let us return to expression \((3.2)\) and put the results \((3.4)\) into it.
Pay attention to the expressions in square brackets - they completely coincide, only the number of summation components differs, i.e. after the subtraction only those components that are not in the subtractor will remain:
Let us discuss the interim results. We have shown that expression \((3.2)\) which we need to prove is equivalent to expression \((3.5)\), so by proving expression \((3.5)\) we arrive at the truth of expression \((3.2)\).
Let us perform a number of transformations on the expression \((3.5)\).
Given that the expression \(\frac{1}{n-\sum_{i=1}^n y_i}\) is non-negative. To fulfil the last identity it is necessary that:
Consider the sum in square brackets:
Let’s rewrite it in a simpler way, but keeping in mind that the summation is carried out only on observations with the manifestation of the trait:
Where
Now recall that \(TPR\) is the proportion of customers, with manifestation, of the trait for whom the manifestation of the trait was predicted. And it can be written as:
Returning to the identity \((3.6)\) and using the results \((3.7)\) and \((3.8)\) we obtain:
Finally:
By proving this identity we prove that the whole chain of identities above is fulfilled. There is already a very similar proof presented here. Let us give a similar proof for our example.
Let’s spell out the expression on the left:
There are not enough even numbers in the summation add and subtract them:
We combine and conjugate the components of the first and second curly brackets and take 2 out of the second brackets:
Returning to the summation operator we obtain:
In the resulting expression, an expression of the form occurs twice:
Here you can find that:
So:
Using the last results in \((3.9)\):
Finally:
Thus the identity \((3.6)\) is fulfilled, followed by the correctness of the identity \((3.5)\) and followed by the correctness of the identity \((3.1)\) \(\boxtimes\).